Listing S3 Buckets with Lambda and OpenGraph
Automatically generating sitemaps for S3 buckets using AWS Lambda.
An S3 bucket combined with a CloudFront distribution can be used to serve static content in a cheap and easy manner. In this case, the static content is web applications that have been synced to S3 from a CI/CD pipeline. Each application is its own directory at the bucket's root, which is served by CloudFront from https://apps.ben.website such that an application's URL becomes https://apps.ben.website/<APP_NAME> - e.g., apps.ben.website/app_1.
. ├── app_1 │ ├── index.html │ ├── ... │ └── abc123.js ├── app_2 │ ├── index.html │ ├── ... │ └── abc123.js ...
With CloudFront, there is a default root object option that applies to requests for the root URL and serves a specified object. This means you can configure CloudFront to resolve foo.com as foo.com/bar.baz. However, this behavior doesn't extend to 'sub-directories' of the origin - or in other words, you can't do the equivalent of "if navigating to foo.com/*/ then actually return foo.com/*/index.html. Fortunately, we can apply this behavior ourselves with a CloudFront function triggered by a viewer request event.
function handler(event) { var request = event.request // case of navigating elsewhere in the site var splitUri = request.uri.split('/') if (splitUri[splitUri.length - 1].indexOf('.') < 0) { request.uri += '/index.html' } return request }
I like this setup because I can create new hosted applications without provisioning new infrastructure. However, without some form of a sitemap, it's unclear how to navigate to the apps in the S3 bucket unless you know the exact name of the S3 object it is filed under.
The solution is to use a lambda function that generates the sitemap as an HTML file and syncs it to the S3 bucket with the key index.html. The lambda function is triggered by an S3 object event, so uploading any changes to the shared app bucket from the app's CI/CD pipeline will result in an updated index.
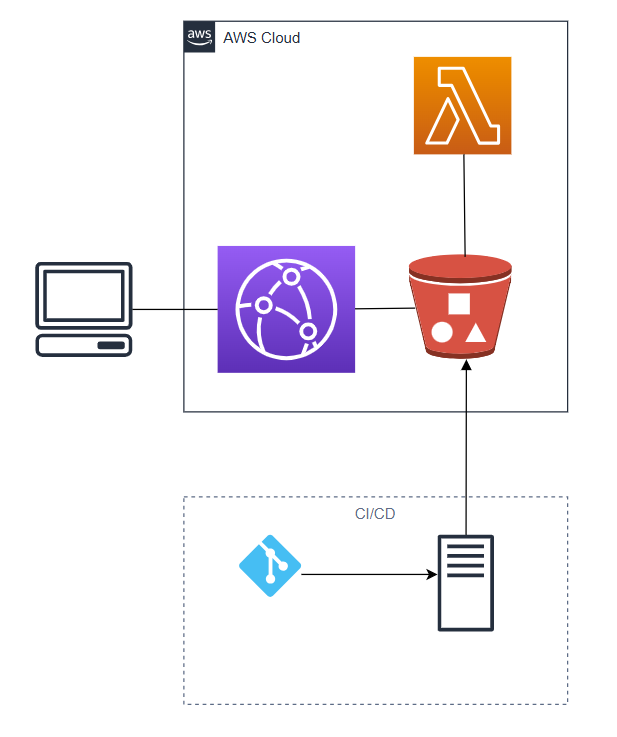
Triggering the Lambda Function
We start by defining a the permissions the Lambda function will need in order to list, get and put objects to the S3 bucket origin.
resource "aws_iam_role" "lambda_role" { name = "lambda-role-multi-app-hosting" assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [{ Effect = "Allow" Principal = { Service: [ "lambda.amazonaws.com", ] } Action = "sts:AssumeRole" }] }) } resource "aws_iam_policy" "assets_bucket_access_policy" { name = "s3-access-policy-multi-app-hosting" policy = jsonencode({ Version = "2012-10-17" Statement = [ { Effect = "Allow" Action = [ "s3:ListBucket", "s3:GetObject", "s3:PutObject", ] Resource = [ "arn:aws:s3:::multi-app-hosting-default-dev.bgoodman", "arn:aws:s3:::multi-app-hosting-default-dev.bgoodman/*" ] } ] }) } resource "aws_iam_role_policy_attachment" "assets_bucket_access_policy_attachment" { role = aws_iam_role.lambda_role.name policy_arn = aws_iam_policy.assets_bucket_access_policy.arn }
The Lambda function itself is unremarkable - a NodeJS setup with an environment variable for the S3 bucket name. The function's trigger is a aws_s3_bucket_notification which observes changes to any *.js file. It is crucial to include this filter since it prevents recursive invocations whenever the sitemap html file is uploaded to the bucket.
# builds lambda source code and generates a zip archive module "sitemap_generator_payload" { source = "gitlab.com/ben_goodman/lambda-function/aws//modules/code_builder" version = "4.0.0" working_dir = "${path.module}/sitemap_generator" command = "npm ci && npm run build" archive_source_file = "${path.module}/sitemap_generator/dist/index.js" } # provisions a lambda function with an env. var for the bucket name module "sitemap_generator_lambda_function" { source = "gitlab.com/ben_goodman/lambda-function/aws" version = "4.0.0" function_name = "${var.project_name}-sitemap-generator-${terraform.workspace}" lambda_payload = module.sitemap_generator_payload.archive_file function_handler = "index.handler" memory_size = 512 role = aws_iam_role.lambda_role runtime = "nodejs18.x" environment_variables = { BUCKET_NAME = "multi-app-hosting-default-dev.bgoodman" } } # Allows s3 events to invoke the function resource "aws_lambda_permission" "allow_bucket" { statement_id = "AllowExecutionFromS3Bucket" action = "lambda:InvokeFunction" function_name = module.sitemap_generator_lambda_function.arn principal = "s3.amazonaws.com" source_arn = "arn:aws:s3:::multi-app-hosting-default-dev.bgoodman" } # Triggers the lambda function when a `*.js` file is created or deleted resource "aws_s3_bucket_notification" "bucket_notification" { bucket = "multi-app-hosting-default-dev.bgoodman" lambda_function { lambda_function_arn = module.sitemap_generator_lambda_function.arn events = ["s3:ObjectCreated:*", "s3:ObjectRemoved:*"] filter_suffix = ".js" } depends_on = [aws_lambda_permission.allow_bucket] }
Generating a Sitemap
This is the bucket we want to map. The goal is to write a function to get an array of object keys representing each application. We'll do this by listing the bucket's objects and filtering them for index.html files - each being the entry point of an application.

We start by listing all objects in the bucket.
const getObjects = async (): Promise<string[]> => { const s3 = new S3() const objects = await s3.listObjectsV2({ Bucket: BUCKET_NAME }).promise() const objectKeys = objects.Contents?.map((object) => { return object.Key }) return objectKeys }
The array of object keys is filtered to only return those ending in /index.html. This excludes the site map since its key does not start with a slash.
const objectKeys = await getObjects() // get keys ending in /index.html const indexObjects = objectKeys.filter((key) => key.endsWith('/index.html'))
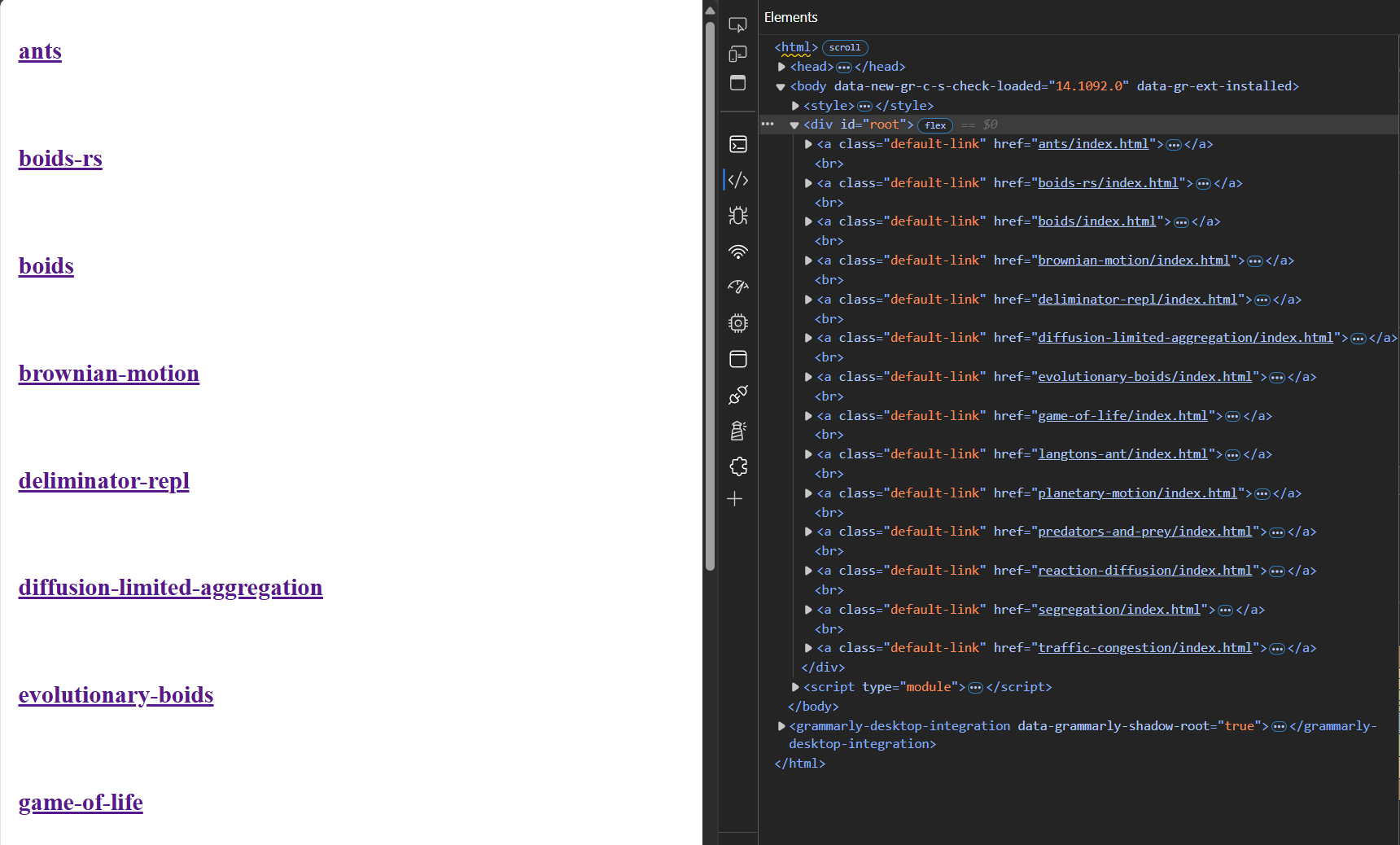
The array is then used to generate anchor tags, allowing the user to navigate to each app.
const links = indexObjects.map((object) => { const dirName = object.split('/')[0] return `<a class="default-link" href="${object}"><h2>${dirName}</h2></a>` })
This results in a simple list of links which can be joined with br tags and wrapped in a div.
<div id="root"> <a class="default-link" href="ants/index.html"> <h2>ants</h2> </a> <br> <a class="default-link" href="boids-rs/index.html"> <h2>boids-rs</h2> </a> <br> <a class="default-link" href="boids/index.html"> <h2>boids</h2> </a> <br> <a class="default-link" href="brownian-motion/index.html"> <h2>brownian-motion</h2> </a> ... </div>
This forms the basis for the index.html document, which will be written to the root of the S3 bucket whenever the Lambda function runs.
export const handler = async (event: S3Event ) => { const objectKeys = await getObjects() // get keys ending in /index.html const indexObjects = objectKeys.filter((key) => key.endsWith('/index.html')) // generates a complete html document with application links as anchor tags. const indexHtml = generateIndexPage(indexObjects) // put the objects into an s3 object /index.html await s3.send(new PutObjectCommand({ Bucket: BUCKET_NAME, Key: 'index.html', Body: indexHtml, ContentType: 'text/html', CacheControl: 'max-age=0' })) }
At this stage, we now have a functioning sitemap which is automatically generated whenever a javascript file change is observed in the bucket. However, without any additional data, the list is not very descriptive - but we can improve on this by adding OpenGraph metadata to each hosted app and then use that to render something more presentible.
Enabling OpenGraph
OpenGraph is the protocol responsible for creating the website previews which appear in rich text media when referencing a URL. The presented data is defined in the site's html document using meta tags. Each application in the S3 bucket has an index.html similar to the one below and contains the app's name, a description, its URL and a link to a preview image. This information will be retrieved by the client when the page loads and used to replace the standard hyperlinks which the Lamba function generates.
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta property="og:title" content="Predators and Prey"> <meta property="og:description" content="Simulated populations of sheep and wolves."> <meta property="og:url" content="https://apps.ben.website/predators-and-prey"> <meta property="og:image" content="https://apps.ben.website/predators-and-prey/index.png"> <link rel="stylesheet" href="./index.css"> <title>Predators & Prey</title> </head> <body> <div id="root"></div> <script type="module" src="./src/index.ts"></script> </body> </html>
The OpenGraph logic is a small block of Javascript embedded in the generated sitemap html file. It's very important to not include any additional Javascript files since that will invoke the Lambda function (recursivley, in this case). The script uses the npm package fetch-opengraph which retrieves OpenGraph metadata from a given URL as a JSON obejct that will be used to create a more informative link, complete with a preview image and description.
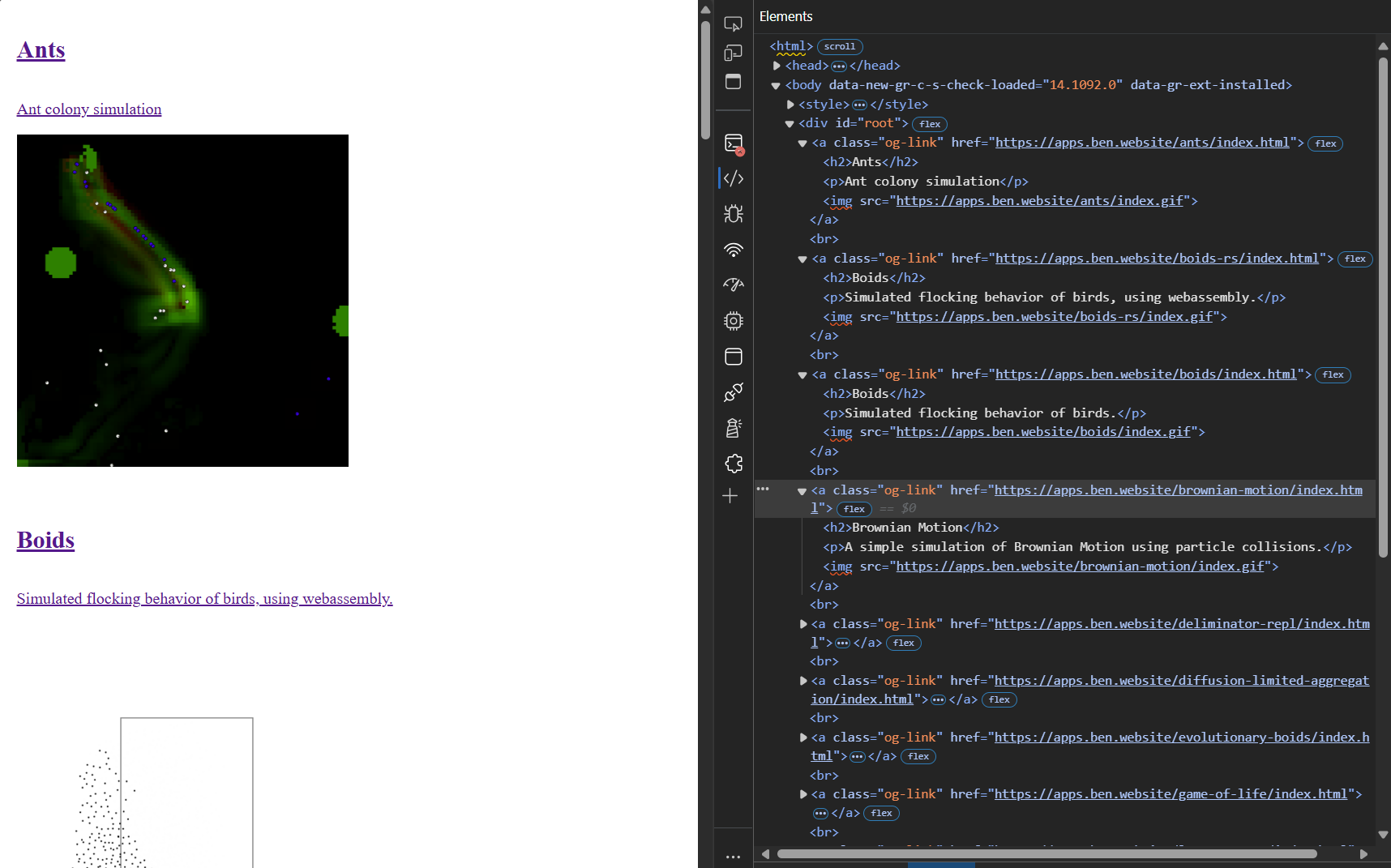
import { fetch as fetchOpengraph } from 'https://cdn.jsdelivr.net/npm/fetch-opengraph@1.0.36/+esm' // enumerate the Lambda-generated links const links = document.querySelectorAll('.default-link') // replace each one with a metadata-based preview links.forEach((link) => { fetchOpengraph(link.href).then((data) => { const title = data.ogTitle ? data.ogTitle : data.title const description = data.ogDescription ? data.ogDescription : data.description const image = data.ogImage ? data.ogImage.url : data.image const url = data.ogUrl ? data.ogUrl : data.url const html = ` <a class="og-link" href=\${url}> <h2>\${title}</h2> <p>\${description}</p> <img src="\${image}" /> </a> ` link.outerHTML = html }) })
When the page loads, the default links are replaced with the new OpenGraph previews.
Conclusion
Its a little janky in places, but the system works remarkably well and is reliable to the point of forgetting it exists. The code for the multi-app hosting infrastructure is here and an example app using it is here.